Step3
综合介绍
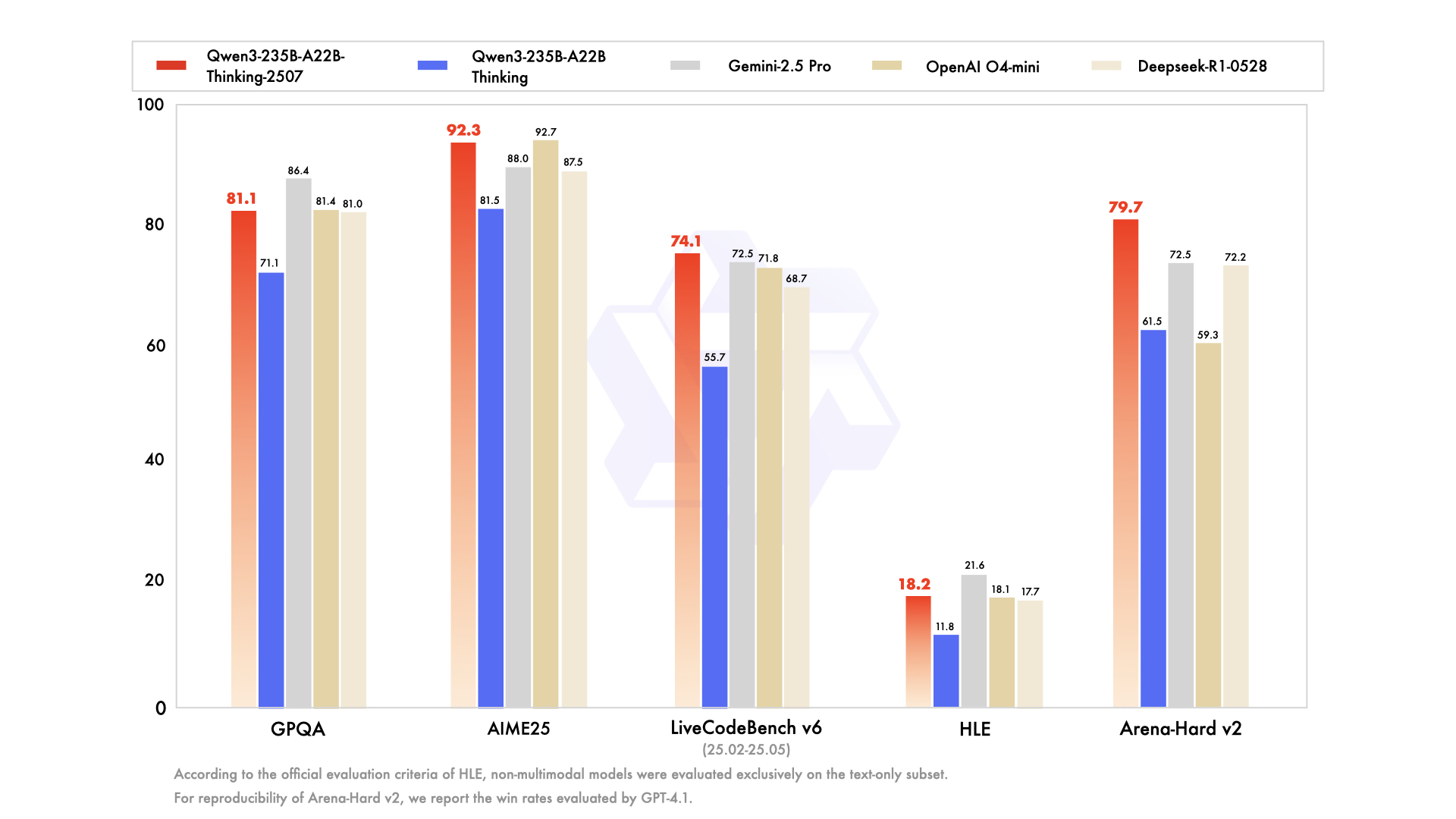
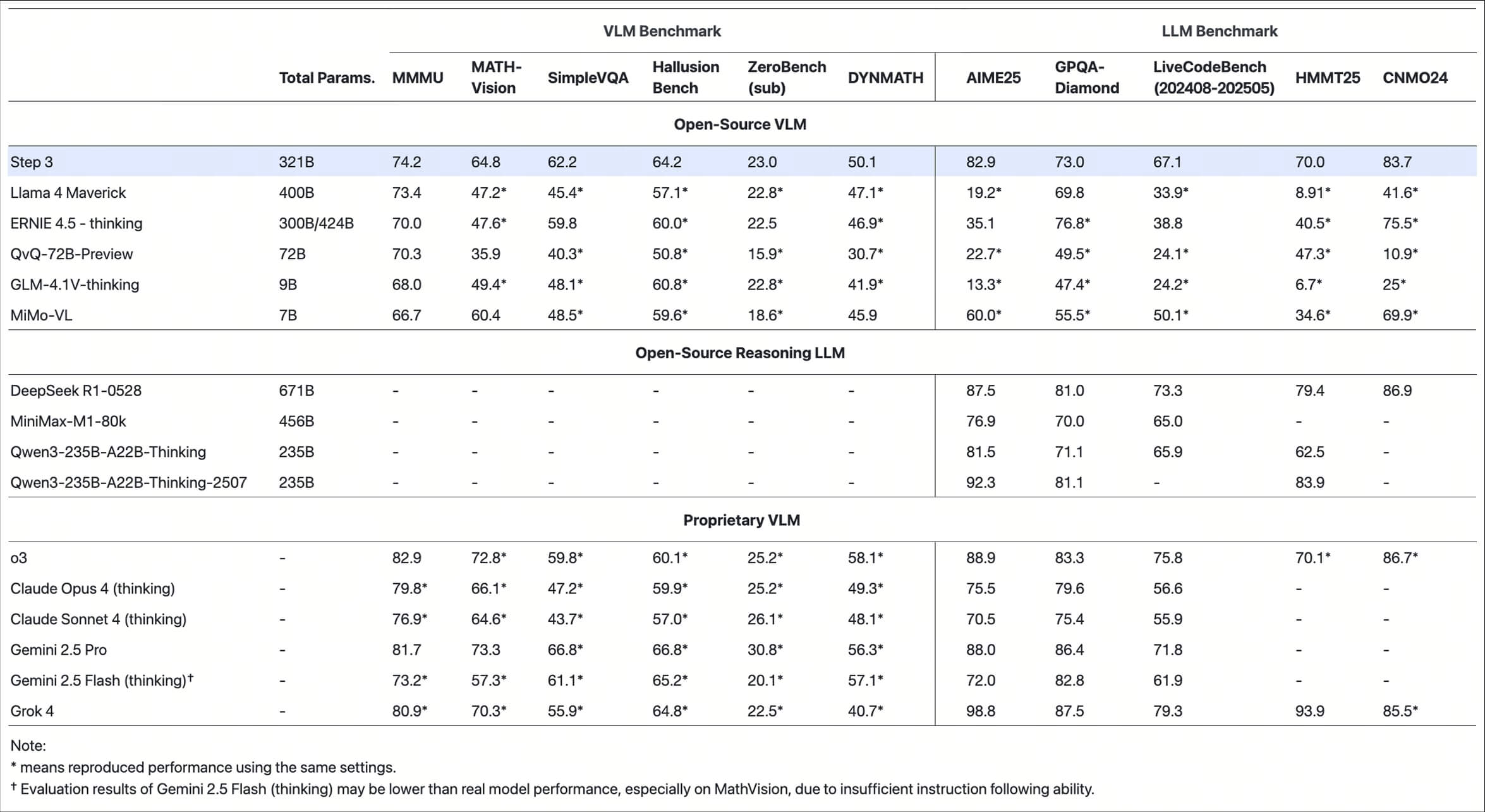
Step3是由阶跃星辰(StepFun)团队开发的一款前沿的多模态推理大模型。它基于拥有3210亿总参数的混合专家(Mixture-of-Experts, MoE)架构构建,每次推理仅激活380亿参数。这种设计的核心目的是在保证顶级视觉语言推理能力的同时,最大限度地降低解码成本。通过模型与系统的协同设计,例如创新的多矩阵分解注意力(MFA)和注意力-前馈网络解耦(AFD)技术,Step3能够在各种主流和低端加速器上都保持出色的运行效率。根据其发布的技术报告和性能评测,Step3在多个基准测试中表现优于同类模型。该模型的代码和权重遵循Apache 2.0开源许可协议,用户可以通过其官方网站获取API服务,也可以在Hugging Face等平台上找到模型权重,并使用vLLM或SGLang等推理引擎进行本地部署。
功能列表
- 高效推理架构:采用混合专家(MoE)架构,总参数量321B,激活参数量38B,显著降低了计算成本。
- 模型系统协同设计:通过多矩阵分解注意力(MFA)和注意力-前馈网络解耦(AFD)技术,优化硬件利用率,提升解码效率。
- 强大的多模态能力:经过超过20T的文本Token和4T的图文混合Token训练,支持复杂的视觉语言推理任务。
- 长上下文处理:最大支持65536个Token的上下文长度,能够处理更复杂的长文本和多轮对话。
- 兼容OpenAI的API:提供与OpenAI/Anthropic兼容的API接口,方便开发者快速迁移和集成。
- 开源和可部署:模型权重在Hugging Face上开源,支持使用
vLLM和SGLang等业界主流的推理框架进行本地部署。 - 支持多种数据格式:模型检查点以
bf16和block-fp8格式存储,兼顾了精度和性能。
使用帮助
你可以通过两种主要方式使用Step3模型:调用云端API或进行本地部署。
1. 使用官方API服务
对于希望快速集成和使用的开发者,最简单的方式是直接调用Step3的官方API。
操作流程:
- 访问StepFun的官方平台
https://platform.stepfun.com/。 - 注册并获取API密钥。
- 查阅API文档,了解接口的调用方式。其API与OpenAI和Anthropic的格式兼容,如果你之前使用过这两家的API,可以很轻松地进行切换。
API调用示例 (Python):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 替换成你的StepFun API密钥
base_url="https://platform.stepfun.com/v1" # StepFun的API地址
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "你好,请介绍一下你自己。",
}
],
model="stepfun-ai/step3", # 指定使用的模型
)
print(chat_completion.choices[0].message.content)
2. 本地部署
对于需要更高灵活性和数据隐私性的场景,你可以将Step3模型下载到本地服务器进行部署。官方推荐使用vLLM或SGLang作为推理引擎,因为它们针对此类大模型进行了深度优化。
环境准备
进行本地部署前,请确保你的环境满足以下基本要求:
- Python 3.10 或更高版本
- PyTorch 2.1.0 或更高版本
- Transformers 库 4.54.0 或更高版本
- CUDA环境和NVIDIA驱动程序(如果使用GPU)
- 至少一张拥有足够显存(例如NVIDIA A100或H100)的高性能GPU
使用Hugging Face Transformers进行推理
这是一个基础的推理方法,适合快速验证和测试。
安装依赖:
pip install torch transformers accelerate
推理代码示例:
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
# 推荐在Python 3.10, torch>=2.1.0, transformers=4.54.0环境下运行
# 目前仅支持bf16格式推理
model_path = "stepfun-ai/step3"
# 加载处理器和模型
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16, # 使用bfloat16精度
device_map="auto", # 自动将模型分配到可用设备
trust_remote_code=True
)
# 准备输入(文本和图像)
prompt = "请描述一下这幅图"
# image = Image.open("path/to/your/image.jpg") # 如果需要进行图像输入,请加载图像
# 如果有图像输入
# inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
# 如果只有文本输入
inputs = processor(text=prompt, return_tensors="pt").to(model.device)
# 生成回复
generation_output = model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95
)
# 解码并打印结果
response = processor.decode(generation_output[0], skip_special_tokens=True)
print(response)
使用vLLM或SGLang进行高性能部署
为了在生产环境中获得最佳性能(更高的吞吐量和更低的延迟),官方强烈推荐使用vLLM或SGLang。 SGLang是xAI等公司也在使用的推理框架,特别擅长处理高并发请求。
安装SGLang:
pip install sglang
使用SGLang启动服务:你可以使用sglang的命令行工具启动一个HTTP服务,该服务会加载Step3模型并提供一个与OpenAI兼容的API端点。
python -m sglang.launch_server --model-path stepfun-ai/step3 --host 0.0.0.0 --port 8000
启动后,你就可以像调用OpenAI API一样,将请求发送到http://localhost:8000/v1。这种方式极大地简化了生产环境的部署流程。
应用场景
- 智能客服与问答系统凭借其强大的语言理解和生成能力,Step3可以构建能够理解复杂问题并提供准确、详尽回答的智能客服机器人。
- 多模态内容创作Step3可以根据文本描述生成图像,或者对输入的图像进行详细描述和分析,为设计师、营销人员和内容创作者提供灵感和素材。
- 视觉辅助应用在需要图像理解的场景中,例如辅助视障人士理解周围环境、图片内容审核或从产品图片中自动提取信息,Step3都能发挥重要作用。
- 教育与研究在教育领域,Step3可以作为辅助学习工具,解释复杂的科学概念或历史事件。在科研领域,它可以帮助研究人员分析大量的文本和图像数据,加速研究进程。
QA
- Step3模型是免费的吗?是的,Step3的模型权重和代码都基于Apache 2.0许可证开源,你可以免费下载和使用。但如果你使用官方提供的API服务,则可能需要根据使用量支付费用。
- 我需要什么样的硬件来运行Step3?由于Step3是一个大型模型,即使采用了MoE架构,本地部署仍然需要配备高端NVIDIA GPU,例如A100或H100,并拥有至少40GB以上的显存。对于普通用户或没有专业硬件的开发者,推荐使用其官方API服务。
- Step3和其它多模态模型(如GPT-4o)相比有什么优势?Step3的主要优势在于其成本效益。 它通过模型和系统的协同设计,在提供与顶级模型相当性能的同时,显著降低了推理成本。这使得它在需要大规模部署的应用中更具吸引力。
- MoE(混合专家)架构是什么意思?MoE是一种模型架构,它包含多个“专家”网络(通常是前馈网络),每次处理输入时,一个门控网络会选择性地只激活一小部分专家。对于Step3来说,虽然总参数量很大,但每次计算只动用其中一小部分(38B/321B),从而大大减少了计算量和内存占用,提升了效率。